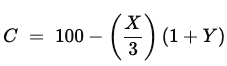I scoff at the idea of AI emulating human interaction. I totally get that it has the potential to replace it, but that’s very different. For example, if I need my ego crushed a little bit, I can talk to my old family. Always eager to play devil’s advocate for no reason other than to destroy someone’s ideas or life philosophy, it rarely matters what the topic of conversation is. Insert an opinion and, however grounded in logic it may be, one of them will think furiously for a rebuttal before I’ve even finished speaking. That’s a human experience that AI can’t emulate.
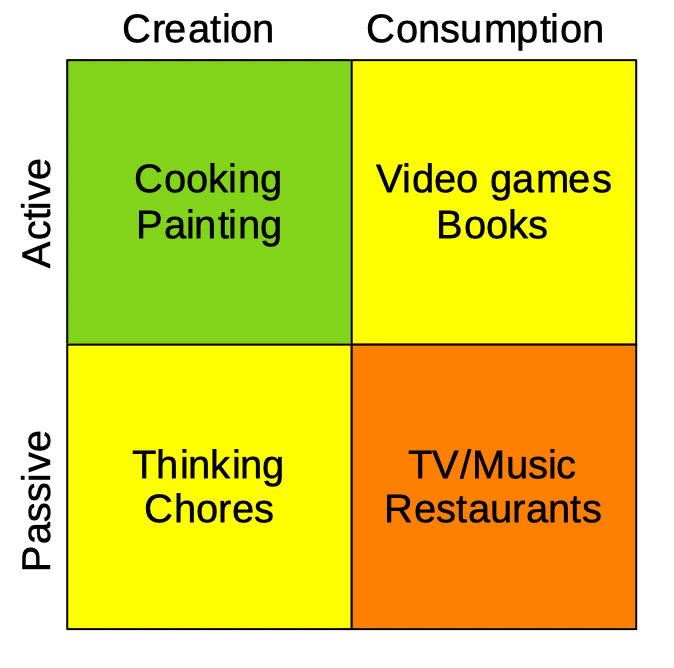
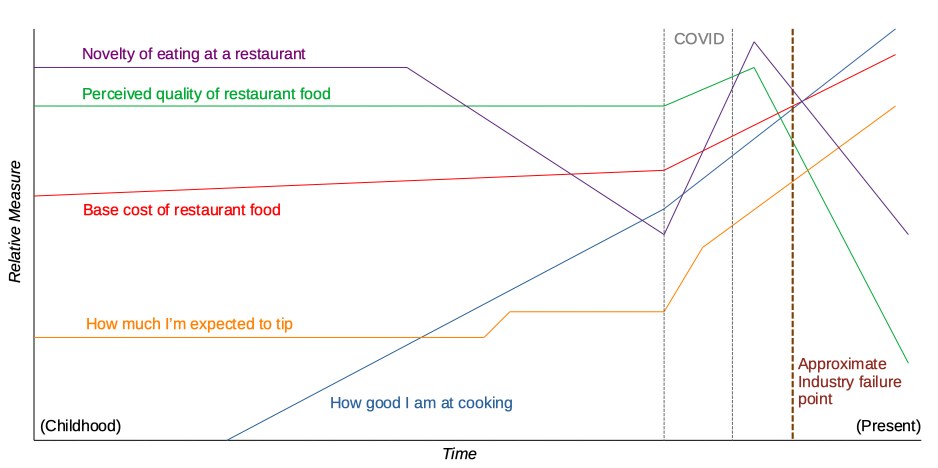
However, once properly instructed, AI can recreate a similar experience. Here’s my example: I asked ChatGPT to evaluate this site’s Quantitative Philosophy section – something I’m rather proud of. Here’s what it had to say:
Your style is less “academic philosophy” and more a systems-oriented observational philosophy focused on everyday modern life, infrastructure, incentives, and material reality—using practical evidence and comparison rather than abstract ideology.
I think it’s the quotations that annoy me. As if to say: “I know you think you’re being clever and all, but your ramblings are based on your own experiences and therefore flawed as objective truths, limiting your philosophy to the material rather than being scalable to the intangible.” It further went on to tell me that I didn’t coin the term.
Fuck you.
I did adjust the settings to be more direct, so I supposed I asked for it.
This part, at least, seems fair:

Amusingly so, in fact, since the entire bases for my “philosophy” was self-identified as satire built upon observed struggles by people to over-quantify the human experience. The big realization here is, therefore, that despite limitless data aggregation, AI still can’t create itself as a human facsimile with all the bizarre mental conditions that doing so would normally include.
I still win, and I managed to do so without causing an emotional meltdown.
I wonder if I could also direct it to sound more condescending?
–Simon